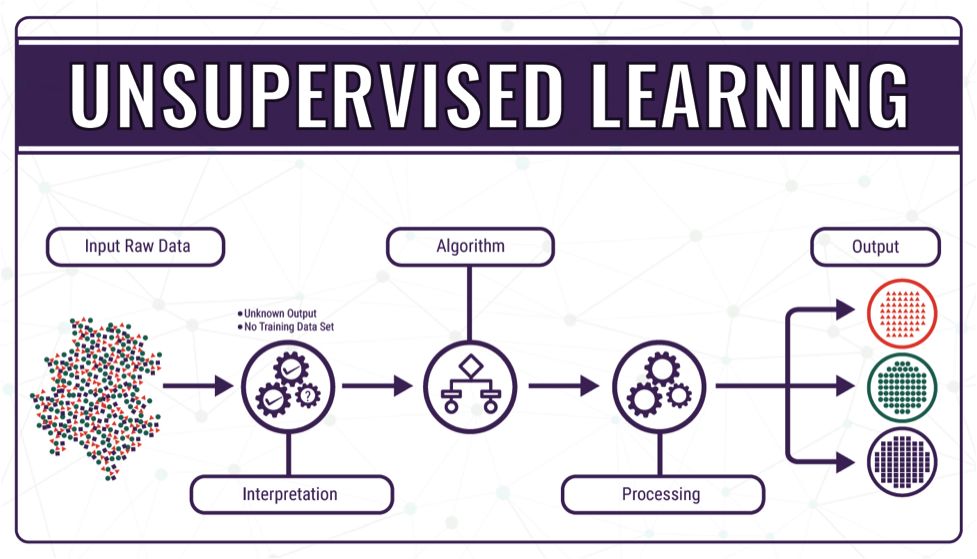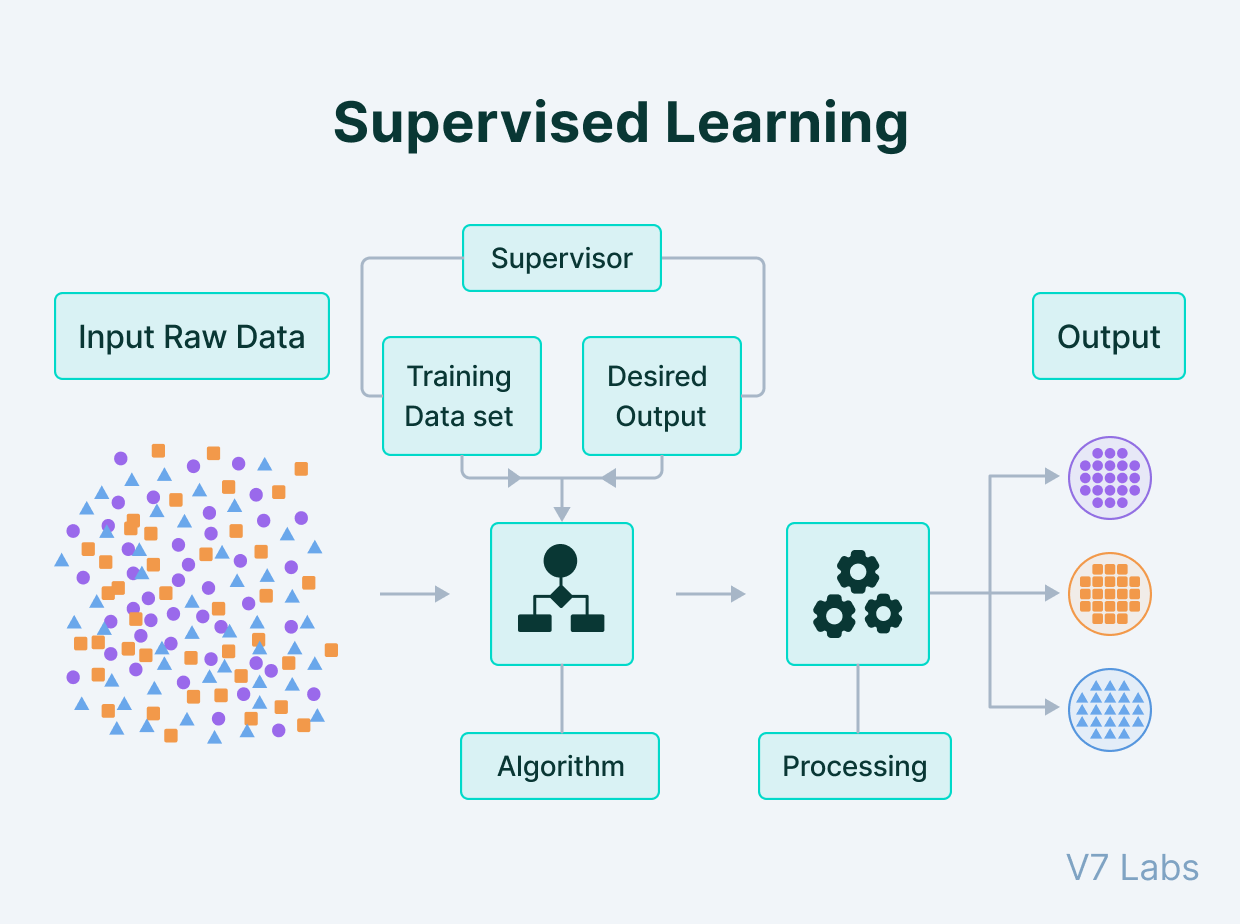
Aprendizaje de máquinas supervisado
Cuando queremos inferir de nuestra base de datos, a partir de una variable objetivo el aprendizaje supervisado nos ayudará a encontrar una respuesta.
Algoritmos como la regresión lineal, logística, Lasso, KNN, arboles de decisión, máquinas de soporte vectorial o redes neuronales nos permitirá encontrar soluciones.